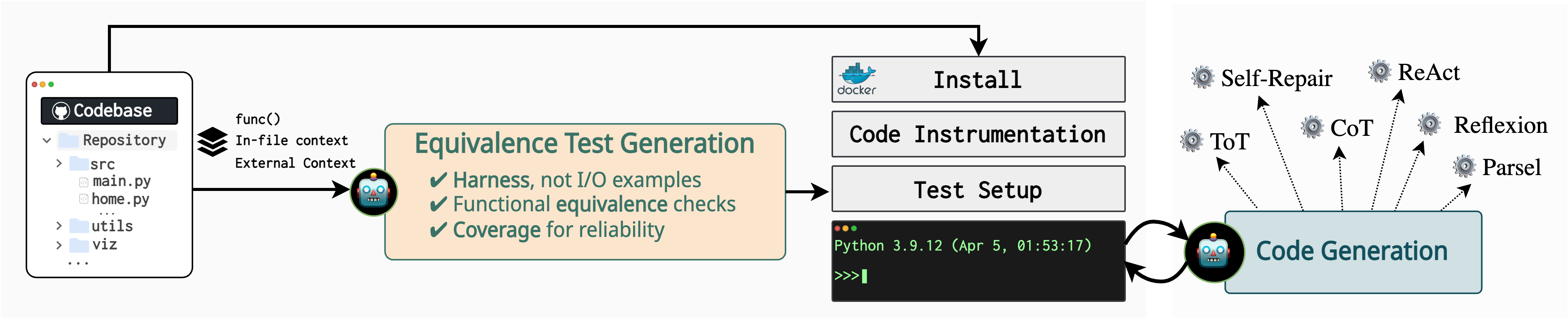
R2E is a framework that turns any GitHub repository into a programming agent environment. This is achieved by a novel equivalence test generation technique powered by a synergy of program analysis and LLMs. These environments can be used for benchmarking static LLMs and dynamic programming agents that can interact with interpreter on real-world (potentially unseen) codebases. Furthermore, R2E environments can also be used for improving LLMs themselves by fine-tuning models with execution traces on such real-world codebases.
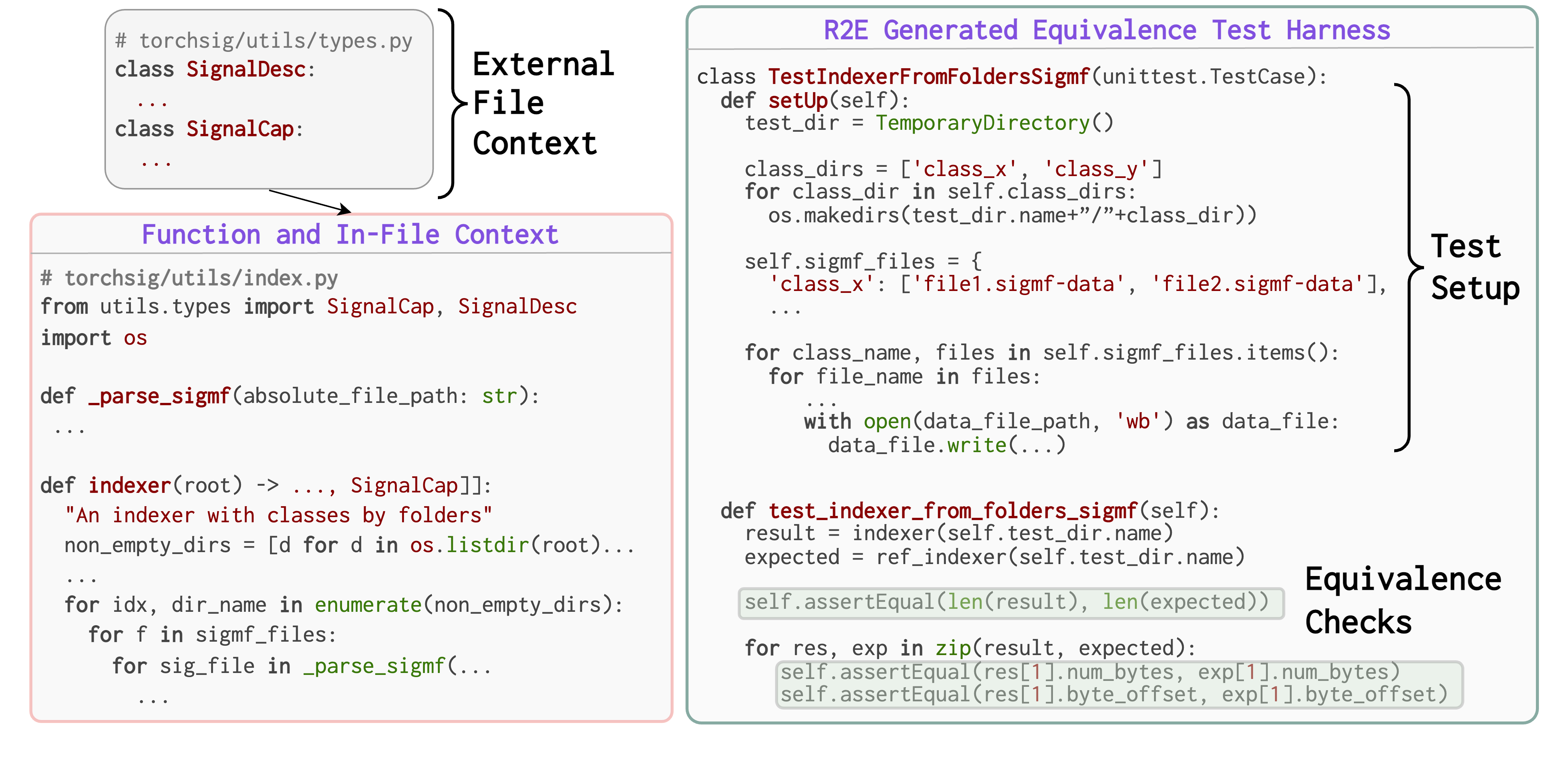 We evaluate the quality of the generated test harnesses by comparing the validity and coverage of the
generated tests. Following table compares the quality of the generated tests for a simple output prediction
setting against our equivalence test generation setting. As we see, the equivalence tests achieve better
validity due to the decoupling of input generation from output prediction. We study different context
creation approaches and find that sliced context is the most effective (see paper for details).
We evaluate the quality of the generated test harnesses by comparing the validity and coverage of the
generated tests. Following table compares the quality of the generated tests for a simple output prediction
setting against our equivalence test generation setting. As we see, the equivalence tests achieve better
validity due to the decoupling of input generation from output prediction. We study different context
creation approaches and find that sliced context is the most effective (see paper for details).
|
In-File
|
Out-File
|
||||
|---|---|---|---|---|---|
| Strategy | Val | Cov | Val | Cov | |
| Output Pred. | 35.43% | 87.59% | 30.68% | 82.54% | |
| Equivalence | 52.37% | 88.18% | 35.01% | 79.65% | |
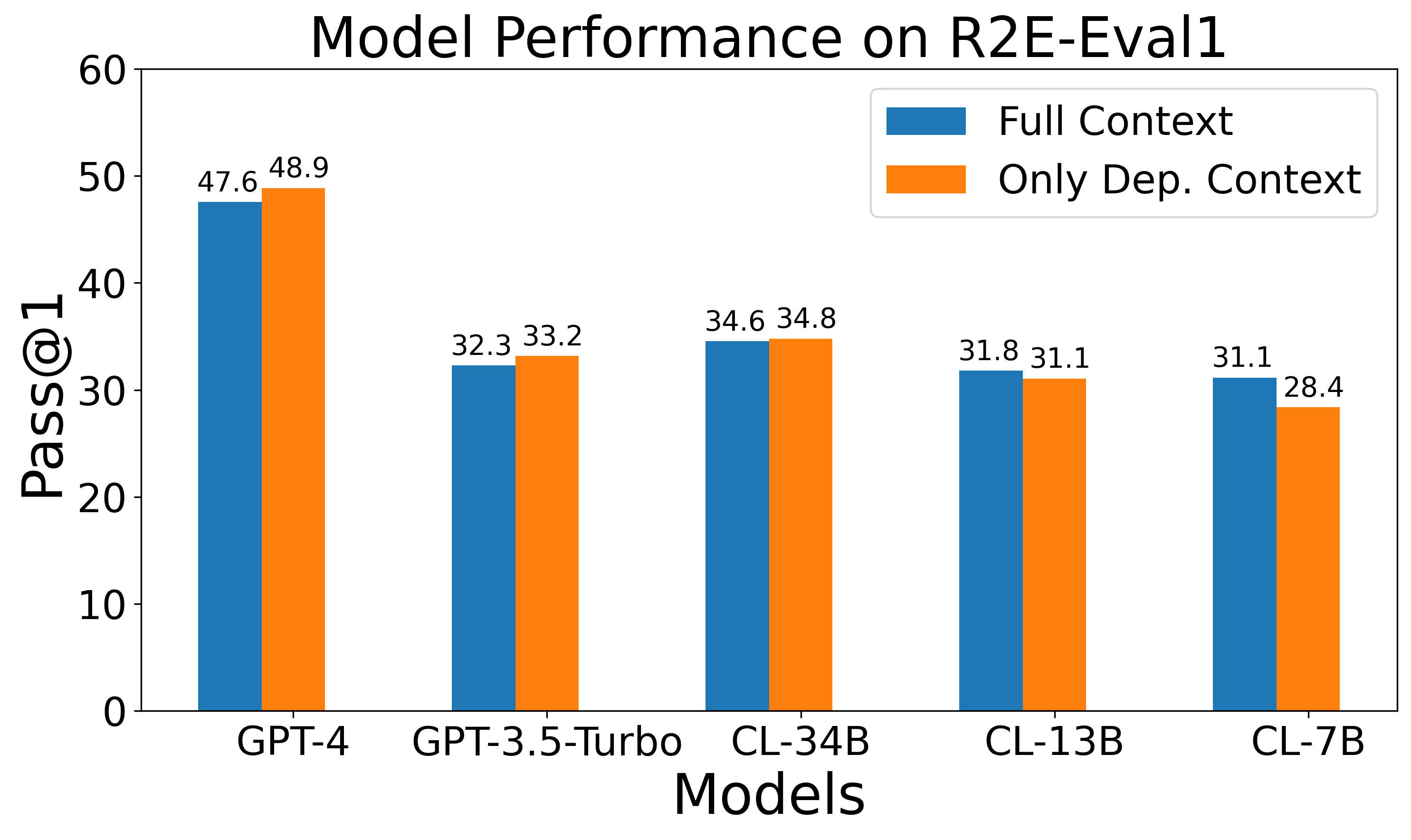
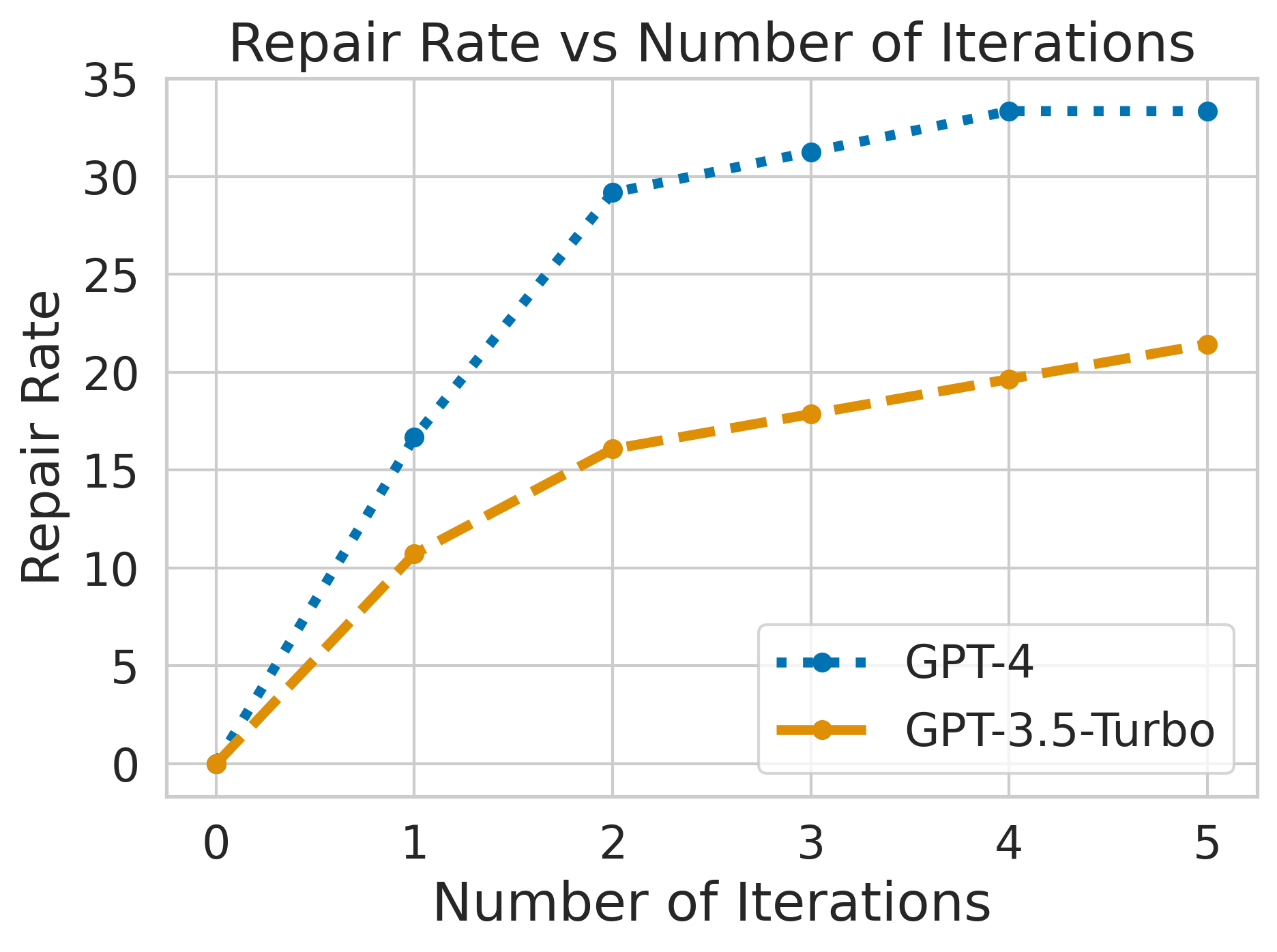
@inproceedings{
jain2024r2e,
title={R2E: Turning any Github Repository into a Programming Agent Environment},
author={Naman Jain and Manish Shetty and Tianjun Zhang and King Han and Koushik Sen and Ion Stoica},
booktitle={ICML 2024},
}